1 Synthetic Data
In this section, we provide a brief introduction to synthetic data along with links to additional resources. This is not intended to be a comprehensive review. For more in-depth information, please refer to the resources listed at the end.
Most of the language comes from our research brief in generating synthetic data for the Nebraska Statewide Workforce & Educational Reporting System (Seeman, Williams, and Bowen (2025)), where the motivating example is based on education to workforce data.
1.1 Introduction
1.1.1 Terminology
The data privacy community includes a diverse range of individuals from both technical and non-technical backgrounds. One of the key challenges in the field is the lack of a shared taxonomy. To support readers in navigating our documentation, we provide the following definitions for terms that will be used frequently throughout.
Figure 1.1 lists the relevant participants in most data ecosystems when safely sharing confidential data.
Confidential data:: a dataset that contains personal or sensitive information that is not publicly accessible.
Synthetic data: a dataset designed to imitate a confidential dataset while limiting information about individual records in the confidential dataset.
Privacy-enhancing technology (PET): a computational or algorithmic process or method used to limit the unintended leakage of personal information in data processing tasks.
Disclosure risk: the risks of unintentionally disclosing personal information about contributors to a confidential dataset by inferring information about them from published statistics or data.
Data utility: the ability for synthetic data to mimic the properties of a confidential dataset, either in general or in specific data processing tasks.
1.1.2 What are Sythetic Datasets?
A synthetic dataset is built to imitate a confidential dataset while limiting information about individual records. Synthetic data can refer to either the methodology used to produce synthetic datasets or the synthetic data output itself (Raghunathan (2021)). In this context, imitating a confidential dataset means the synthetic data have similar statistical properties to the confidential data. Data processing and analysis should produce similar outputs when using either the confidential or synthetic dataset. Synthetic data have higher utility or usability when the outputs from the confidential and synthetic datasets are more similar.
Limiting information about individual records makes it harder for a data adversary to infer information about the data subjects in the confidential dataset. A data adversary should have difficulties inferring whether a data subject contributed their information to the underlying confidential dataset used to generate the synthetic data.
1.1.3 Purposes of Synthetic Data
All data sharing poses some privacy risks, regardless of how the data are released. Simply put, releasing information based on confidential data cannot perfectly preserve both privacy and utility. A perfectly secure dataset is one that is not accessible, which is useless. Conversely, a perfectly useful dataset is one that is released without any privacy protection.
Synthetic data is an example of a privacy-enhancing technology (PET), a computational or algorithmic process used to limit the unintended leakage of personal information in data-processing tasks. Different PETs address different kinds of privacy harms, which may emerge from system design, algorithmic processes, access controls, or other technical aspects of data processing systems. Synthetic data specifically aims to mitigate disclosure risks, or the risks of unintentionally disclosing personal or sensitive information about data subjects that can be inferred from published statistics or data based on a confidential dataset.
Using synthetic data affords the following:
Greater disclosure risk protections: Even when suppressing or removing data fields containing personally identifiable information, providing access to confidential data without further modification can still enable users to infer personal information about individuals in the confidential dataset (Dwork et al. (2017)). Synthetic data involves randomization based on a statistical model to provide greater protection, making such inferences much harder, thus limiting disclosure risks.
Expanded data accessibility: Existing processes for getting access to sensitive datasets can be burdensome. Alternatively, synthetic data can be more easily shared than the confidential data, often requiring only a modest data-use agreement instead of more extensive processes. This reduces the administrative burden for both data curators and data users.
1.1.4 Synthetic Data Benefits and Use Cases
Synthetic data has many possible use cases, including but not limited to…
- Enabling exploratory data analysis on confidential tabular data sources.
- Publishing detailed descriptive statistics about confidential tabular data for reporting purposes.
- Testing data processing applications without direct access to confidential data.
- Streamlining access management processes to confidential data for research purposes.
1.2 How Synthetic Datasets are Generated
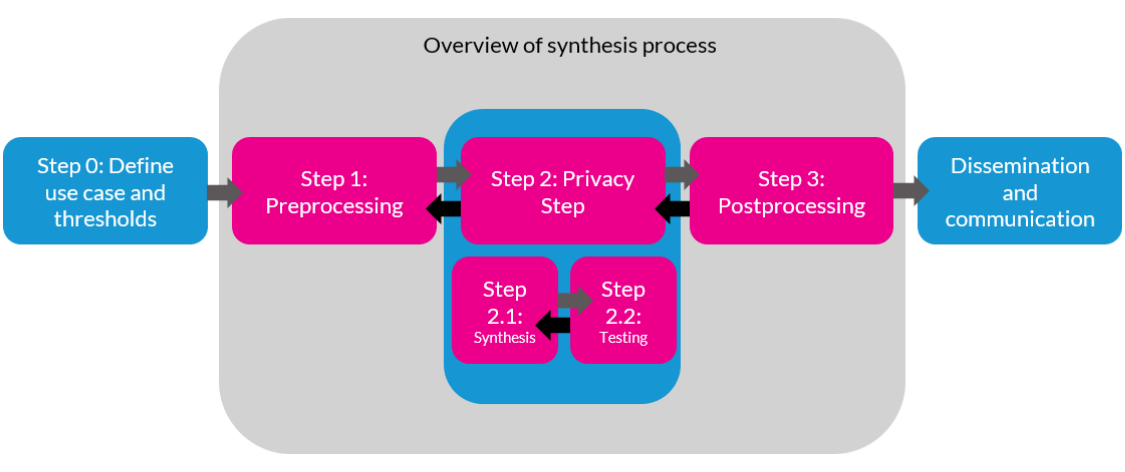
Effective synthetic data deployment involves multiple steps, outlined in Figure 1.2. First, in step 0, data curators work with data users and subjects to define use cases for synthetic data. This critical step ensures that synthetic data meets the needs of prospective data users, which may vary significantly. Some data users may only need a few key variables, such as sociodemographic outcomes and individual outcomes like graduation rates. Other users may need more granular information, such as detailed course enrollment information for individual students. As part of this process, data curators can identify thresholds, or goals for the success of a particular synthetic data task. For example, program evaluators may want to produce statistics that differ by a relative error of no more than 10 percent from those based on the confidential data.
Next, in step 1, data curators or privacy experts work together to preprocess the data. The goal of this stage is to design and create a gold-standard dataset (GSDS), or a dataset that contains all the possible information data users need to perform their analyses. Synthetic data always aims to imitate one specific GSDS, but there are many possible ways to design and produce GSDSs. For example, some education researchers may be interested in student-level synthetic data (one record per student), whereas others may be interested in course-level synthetic data (one record per instance of a particular course).
In the next two steps, we generate and evaluate our synthetic data. In step 2, we use statistical or algorithmic modeling techniques to generate synthetic data based on our GSDS (this is described in more detail in the next subsection). In step 3, we evaluate our synthetic data to ensure it meets our privacy goals and our use case goals. Steps 2 and 3 are often performed iteratively; one might evaluate multiple synthetic data configurations or try new synthetic data configurations motivated by evaluation results.
Finally, in the last step, synthetic data are disseminated to potential data users. Here it is critical to make sure the data users are well-informed about how the synthetic data were generated, how the synthetic data were evaluated, and how the synthetic data should be used in practice. For example, if a synthetic dataset is sufficiently accurate for producing two-way contingency tables but not for complex nonparametric modeling, data users need to know this information to responsibly use their synthetic data.
1.2.1 Synthetic Data–Generation Methods
In general, synthetic data are generated in two stages: first, the data curators or data privacy experts build a statistical model to capture relationships between variables that appear in the confidential dataset. Next, those same experts randomly sample synthetic records or values from these models.
Often, these two stages occur more than once. Many synthetic data methods uses what’s known as fully conditional synthesis. This type of synthesis means new variables (i.e., tabular data columns) are iteratively added one by one to construct synthetic data. For example, suppose we have already synthesized two demographic variables, like gender and age, and we want to synthesize a new variable, whether someone was ever a transfer student. We would first model the proportions of transfer students based on the two demographic variables (e.g., the proportion of males ages 21 to 24 that are transfer students). Then, we would randomly sample new values for each synthetic record’s transfer student status according to this model.
Crucially, synthetic data only allow users to perform statistical analyses that are supported by the synthesis process. If a synthetic data user is interested in investigating a particular aspect of the confidential data distribution, that aspect must be accounted for as part of the modeling process. Continuing the previous example, suppose we modeled the proportion of transfer students based only on age, not age and gender. This would prevent a synthetic data user for investigating the three-way relationship between gender, age, and transfer-student status because the synthetic data model assumes one’s gender is not associated with their transfer-student status.
1.2.2 Modeling Considerations
All synthetic data’s effectiveness hinges on successful model building. The following considerations have the biggest impact on both disclosure risks and utility; see (Drechsler et al. (2024)) for more methodological details.
Synthesis inputs and ordering. When using fully conditional synthesis, not all variables can be effectively modeled using the same predictor variables. For example, if a model for graduation rate relies on predictors that fail to capture statistically meaningful differences in graduation rates, the resulting synthetic data may be lower quality or have less utility. This situation is why it is important to synthesize variables in an order that captures increasingly complex relationships. Doing so improves the quality of variables synthesized later in the process.
Model complexity. There are countless different methods for modeling the relationships between variables. Generic model fitting methods (sometimes known as nonparametric, empirical or “black box” methods) allow for the construction of more complex, flexible models than simpler methods (such as parametric or generative models like regressions). For example, the relationship between degree programs and income is quite complex and can be more effectively modeled using generic methods. Although more complex models can produce higher utility synthetic data, they can also produce models that overfit to the confidential data, leaking information about data subjects in the process.
1.3 How Synthetic Data are Evaluated
Synthetic data must always be evaluated to ensure both sufficient utility and disclosure risk protection prior to being publicly released or being accessed by data users. Evaluating synthetic data helps data curators communicate about how synthetic should (or should not) be used and the privacy risks involved with making synthetic data more widely available.
1.3.1 Data Utility
Data utility evaluations measure how well synthetic mimics the structural and statistical properties of the confidential data. Evaluations typically involve computing metrics that compare statistics based on the confidential data versus the synthetic data.
There are two main classes of utility metrics (Snoke et al. (2018)). First, general utility (or global utility) metrics measure how distinguishable two entire datasets are from one another. For example, suppose we have a synthetic dataset based on confidential data that contains categorical demographic information about students, such as their county, gender, and race. We could count the number of unique students in each category for each dataset and compute the average difference in counts between the synthetic and confidential datasets.
Second, specific utility metrics measure how similar synthetic and confidential data perform on the same predefined task or analysis. For example, suppose we wanted to estimate a regression coefficient or parameter that describes the association between transfer student status and graduation rates. We could apply the regression analysis to compute the parameter estimate on the synthetic and confidential datasets separately. We then compare the signs, magnitudes, uncertainties, and so on, of the synthetic and confidential estimates.
1.3.2 Disclosure Risk
Disclosure risk refers to the ability to infer information about data subjects in confidential datasets using publicly released statistics, synthetic datasets, or other resources that are based on the confidential data. Disclosure risk metrics depend heavily on assumptions about what information might be available about how synthetic data were generated or the underlying confidential dataset.
Disclosure risk metrics capture different kinds of inference about data subjects:
Membership inference measures how well someone can infer the presence or absence of data subjects within the confidential dataset. For example, can a prospective data user infer whether someone they know contributed their information to the data curator in the synthetic dataset?
Attribute inference measures how well someone can infer information about data subjects within the confidential dataset. For example, can a prospective data user infer a data subject’s ACT score using the synthetic data? Note that given sufficient background information, successful attribute inferences can also reveal specific data utility. In other words, some synthetic data models that produce higher utility will capture relationships between variables that exist within the broader population, not just the specific confidential sample. For example, if graduation rates differ by age in the general state population, one could use age to estimate graduation rates for individuals within education data.
Disclosure risk metrics also come in two flavors:
Empirical metrics describe how effectively and practically someone can use synthetic data to infer information about data subjects in the confidential dataset. For example, a data adversary could generate multiple synthetic data samples and measure the frequency of more unique individuals within the synthetic data and their relationship to the confidential data.
Formal metrics describe how effectively the process that generates synthetic data provides protection. For example, PETs like differential privacy can measure the amount of randomized noise is injected into the synthetic data-generation process (Dwork, Roth, et al. (2014)).
1.4 Frequently Asked Questions
1.4.1 Are Synthetic Data “Fake Data”?
The word “synthetic” can evoke negative connotations about data appearing inauthentic or deceptive. Such connotations often deter data curators from adopting synthetic data due to anxieties about institutional or reputational harms from releasing “fake” data products. Although concerns about data quality and responsible data usage are important, these concerns apply to any data product, synthetic or not. Modifications to raw data, such as input error correction, imputations of missing values, or record linkages, result in statistical decisions by a user that affect the analysis. Alternatively, we should view synthesis as another part of the data-making process, where greater transparency about data-production processes can enable more responsible use.
1.4.2 How Do I Validate or Provide a Validation Process for Synthetic Data?
Validation processes allow data users to ensure that results produced based on synthetic data are like those that could be hypothetically produced by the confidential data. Different approaches to validation rely on answering a few design questions. First, how would data users interact with the validation process? Some may submit manual requests to data curators, whereas others may rely on automated interfaces, such as validation query systems. Second, what kinds of validation metrics would be surfaced to users? Some validation processes provide exact statistics that quantify precise differences between confidential and synthetic results, whereas others use PETs to protect the validation results themselves. Finally, how might data users use the results of the validation process? Some processes allow for all validation results to be released publicly, but others may be omitted or suppressed due to disclosure risk concerns.
1.4.3 How Do I Help Users Effectively and Responsibly Use Synthetic Data?
New users of synthetic data may be tempted to directly substitute confidential data for synthetic data, but making this substitution without additional considerations could be dangerous in the wrong setting. User education is the most effective tool to enable responsible use and prevent potential misuse. Most importantly, responsible user education starts with explicit disclaimers about how synthetic data was generated and what the synthetic data should and should not be used for in downstream applications. More comprehensive user education can take many forms, including reporting on synthetic data evaluations, trainings, and other learning resources.
1.4.4 How Do I Decide What Confidential Datasets to Synthesize?
Synthetic datasets should always be motivated by use cases where the GSDS (i.e., the data to synthesize) is reasonably inaccessible and the data curators could feasibly synthesize a dataset meeting a critical mass of use-case needs. Many decisions about how to select your GSDS should be driven by use cases; for example, if only a small subset of questionnaire items is regularly used in a survey instrument, it would be wise to prioritize synthesizing only these heavily used questionnaire items.
1.5 Additional Resources for Further Reading
- Synthetic Data for the Nebraska Statewide Workforce & Educational Reporting System
- Synthetic Data
- Synthetic Data: A Look Back and A Look Forward
- Advancing microdata privacy protection: A review of synthetic data methods