string1 <- "This is a string"
string2 <- 'If I want to include a "quote" inside a string, I use single quotes'Strings and Regular Expressions
Strings are what characters or words are called in R. Strings are declared with either a single ' or double " quote.
library(stringr)
library(stringr) contains powerful and concise functions manipulating character variables. Reference the cheat sheet for an overview of the different string manipulation functions. This library has a ton of helpful functions and so I think the most helpful this is to know what R can do with strings and then look up how to do that.
Detect Matches
str_detect() is particularly helpful if you want to select variables that have certain character stings in them. For example:
string_list <- c("Blue", "Red", "Green")
str_detect(string_list, "Blue")[1] TRUE FALSE FALSE| Function | Use | Visual |
|---|---|---|
str_starts() and str_ends() |
Detect pattern matches at the start or end of a string | 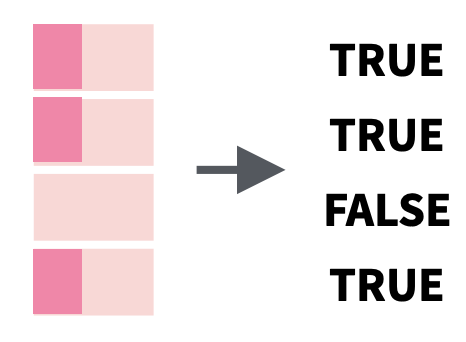 |
str_which() |
Find the index (location in a list) of a string that contains the pattern match | 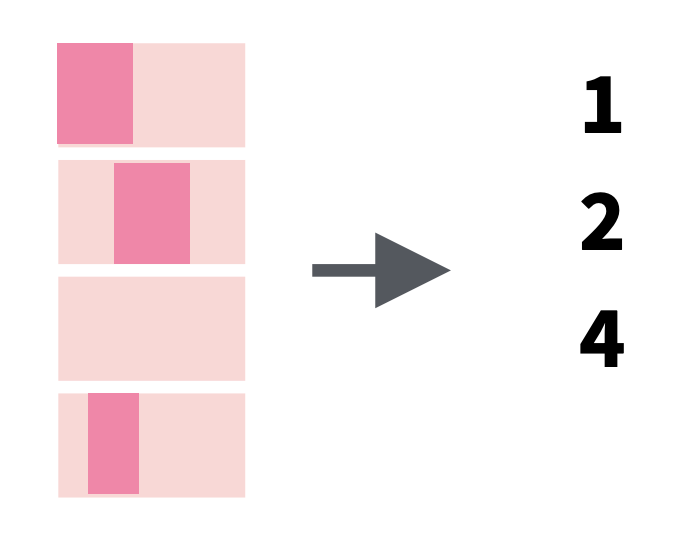 |
str_locate() and str_locate_all() |
Locate the position of the pattern match in the string | 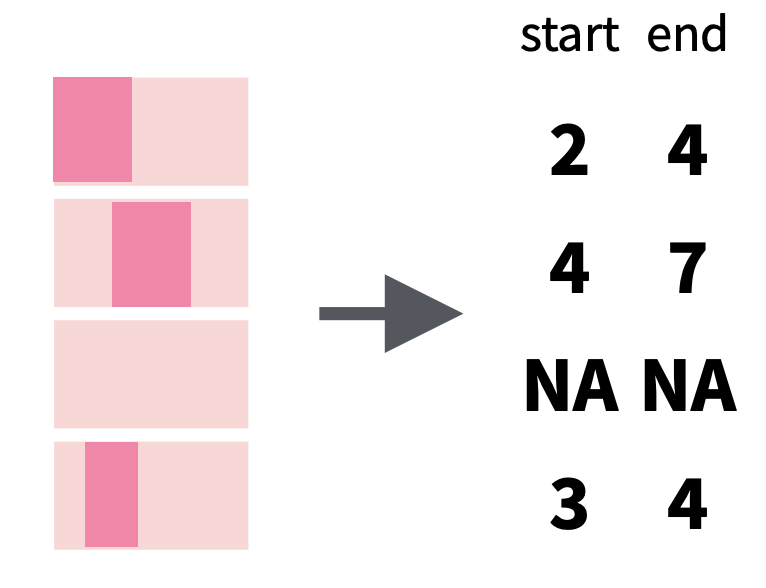 |
str_count() |
Count the number of matches in the string | 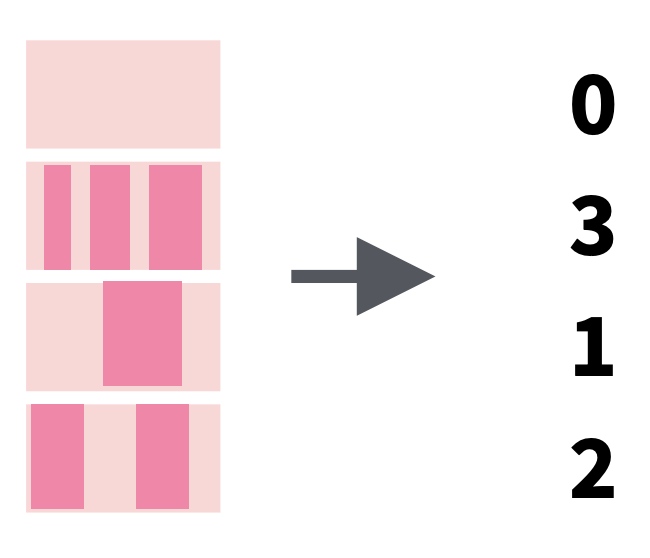 |
Visuals from stringr cheatsheet
Subset Strings
Subletting strings can be useful if you only want just one part of the word or to drop a certain section for data cleaning. For example:
string_list <- c("Blue, Green", "Green, Silver", "Silver, Red")
str_subset(string_list, "ee")[1] "Blue, Green" "Green, Silver"| Function | Use | Visual |
|---|---|---|
str_sub() |
Extract characters at a specified location in a string (i.e. the middle 4 characters). | 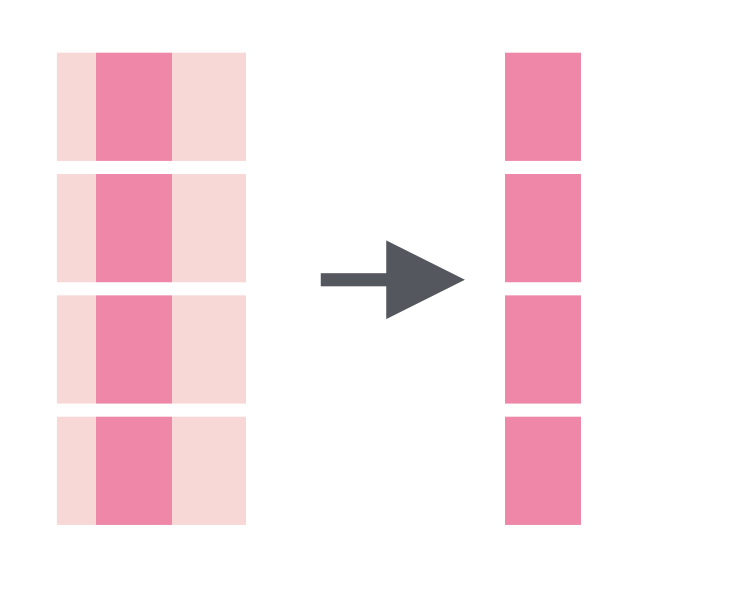 |
str_subset() |
Return strings that contain a pattern match | 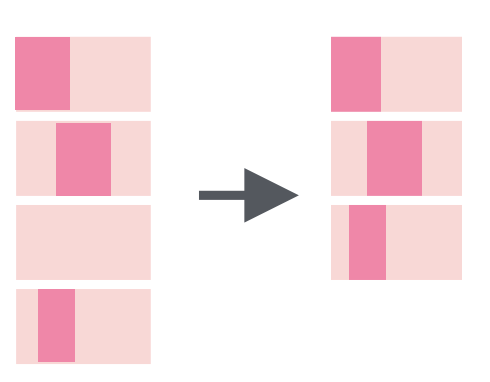 |
str_extract() and str_extract_all() |
Return the first (or all) pattern matches found | 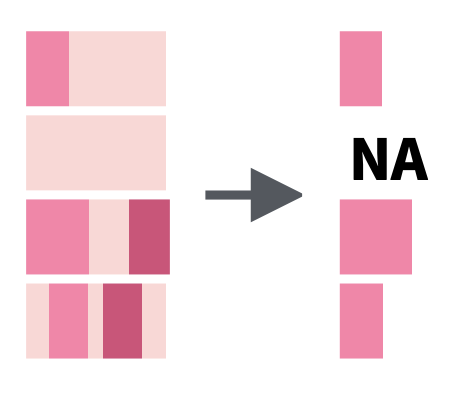 |
Visuals from stringr cheatsheet
Manage Lengths
| Function | Use | Visual |
|---|---|---|
str_length() |
The number of characters in a string | 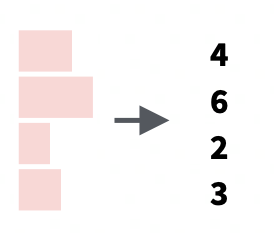 |
str_pad() |
Pads strings to a consistent length (this is useful if you need to add a leading or trailing zero) | 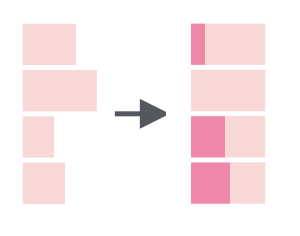 |
str_trunc() |
Truncate the length of a string and replacing content with an elipses | 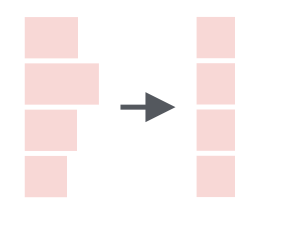 |
str_trim() |
Trim whitespace from the start of end of a string (this is useful if you want to get rid of a leading or trailing space) | 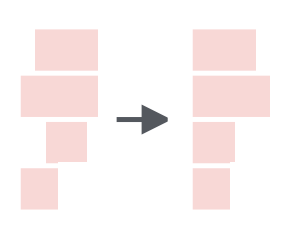 |
str_squish() |
Trim white space from each end and collapse multiple spaces into single spaces (useful for cleaning up string data) |
Mutate Strings
| Function | Use | Visual |
|---|---|---|
str_replace() and str_replace_all() |
Replace either the first, or all, matched patterns in a string with a new value. | 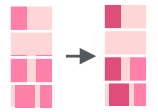 |
str_to_lower() and str_to_upper() and str_to_title() |
Convert strings to all lower, upper or title case - very useful for data cleaning |    |
str_wrap() |
Wraps a string into a nicely formatted paragraph. This is super useful for cleaning up axis labels that run into each other |  |
Join and Split
| Function | Use | Visual |
|---|---|---|
str_c() |
Concatenate multiple strings together with the ability to specify how they’re separated (i.e., with spaces, commas, or backslashes) | 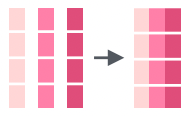 |
str_flatten() |
Combines a list into one single string separated by whatever you specify (e.g., ,turn a list of the first 5 letters of the alphabet into one word - “abcde” | 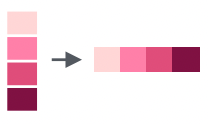 |
str_dup() |
Repeat a string a set number of times | 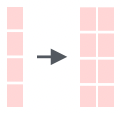 |
str_split() |
Split a string where it matches a pattern (e.g., split at each comma, each “and”, or only the first two “and”) | 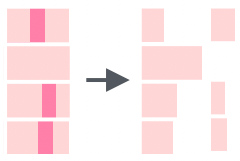 |
str_glue() |
Create a string that has both strings and {expressions} to evaluate - this is useful for creating dynamic or iterative text (e.g., str_glue("Pi is {pi}") |
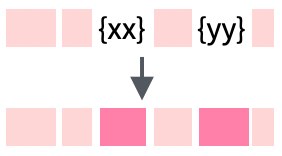 |
Helpers
You can use writeLines() to view how R interprets your string. For example:
writeLines("\\ backslash")\ backslashwriteLines("\tadds a tab because it's a special character") adds a tab because it's a special characterRegular Expressions
Regular expressions are a way to describe patterns in strings. Say you want to find all values that end in "ing", or clean a list of strings to drop the least 5 letters. You might not always know which letters those are, but you know there’s a pattern you want to follow to systemically remove them.
Regular expressions can seem confusing at first, but the most important thing is to understand the general principles of what you can do with it, and then Google the specific syntax for how to do it.
Escaping
There are certain special characters that are used to match a range of options like . which is used to match any character. So what if you want to match a literal period “.”? The solution in regex is a double backslash \\ which escapes special behavior.
| Type This | To Match This |
|---|---|
| \\. | . |
| \\! | ! |
| \\? | ? |
| \\\ | \ |
| \\( | ( |
| \\{ | { |
| \\n | new line (return) |
| \\t | tab |
| \\s | any whitespace |
| \\d | any digit |
| \\w | any full word |
| \\b | word boundaries |
| . | every character except a new line |
Alternates
Alternates are a way to select between one or more possible matches. Note that you can use parenthesis to control the order of operations.
| Regular Expression | Matches | Example |
|---|---|---|
| ab|d | or | abcde |
| [abe] | one of | abcde |
| [^abe] | anything but | abcde |
| [a-c] | range | abcde |
str_detect(c("abc", "def", "ghi"), "abc|def")[1] TRUE TRUE FALSEstr_extract(c("grey", "gray"), "gre|ay")[1] "gre" "ay" str_extract(c("grey", "gray"), "gr(e|a)y")[1] "grey" "gray"Anchors
Anchors are a way to tie the pattern to either the beginning or end of the word. Say you only want to select words that end in “ing” or begin with “March”
| Regular Expression | Matches | Example |
|---|---|---|
| ^a | start of string | aaaa |
| a$ | end of string | aaaa |
x <- c("apple", "banana", "pear")
str_extract(x, "^a")[1] "a" NA NA str_extract(x, "a$")[1] NA "a" NA Look around
Look around searches around the current match without capturing it. This is most useful when you want to check if a pattern exists without including it in the results.
| Regular Expression | Matches | Example |
|---|---|---|
| a(?=c) | followed by | bacad |
| a(?!c) | not followed by | bacad |
| (?<=b)a | preceded by | bacad |
| (?<!b)a | not preceded by | bacad |
x <- c("1 piece", "2 pieces", "3")
str_extract(x, "\\d+(?= pieces?)")[1] "1" "2" NA y <- c("100", "$400")
str_extract(y, "(?<=\\$)\\d+")[1] NA "400"Quantifiers
Quantifiers control how many times a pattern is matched
| Regular Expression | Matches | Example |
|---|---|---|
| a? | 0 or 1 | abca abca aa |
| a* | 0 or more | abcaabcaaa |
| a+ | 1 or more | abcaabcaaa |
| a{n} | exactly n (2) | abcaabcaaa |
| a{n,} | n or more (2) | abcaabcaaa |
| a{n,m} | between n and m (2, 4) | abcaabcaaa |
x <- "1888 is the longest year in Roman numerals: MDCCCLXXXVIII"
str_extract(x, "CC?")[1] "CC"str_extract(x, "CC+")[1] "CCC"str_extract(x, 'C[LX]+')[1] "CLXXX"str_extract(x, "C{2}")[1] "CC"str_extract(x, "C{2,}")[1] "CCC"str_extract(x, "C{2,3}")[1] "CCC"