1 Basics of Data Governance and Privacy

For this introductory chapter, you will learn about:
- Dimensions of data governance and their privacy implications.
- Kinds of trade-offs associated with disclosure risk.
- Definitions and interpretations of data privacy.
1.1 Why is Data Governance and Privacy Important?
Data governance ultimately concerns decision-making around how data flows or does not flow between parties. While different actors may be more concerned with expanding or restricting data flows, real-world harms can occur if data sharing is too permissive or too restrictive.
Recent changes to SNAP administration reveal the limits of both too much data sharing and too little data sharing:
- In October 2025, NPR reported that states turned over personal information on snap recipients to USDA. This new centralization of SNAP data at USDA poses many data governance questions, including but not limited to…
- Legal risk: is this data collection allowed under federal and state law?
- Institutional risk: is this data collection in line with expectations for how federal and state agencies collaborate?
- Data subject protection: is there transparency around how this data will be used, and will there be sufficient protections for data subjects?
- In September 2025, NPR reported that the USDA is canceling the Household Food Security Report. This new redaction on nutritional accessibility data poses many data governance questions, including but not limited to…
- Data alternatives: what alternative data sources might users turn to in place of this report, and are they sufficient replacements?
- Evidence-based decision-making: what kinds of policy decisions at the federal, state, or local level are now lacking evidence due to this report being unavailable?
- Public accountability: how is the USDA justifying its decision to cancel the report, and how are the savings from canceling the report being used?
The following are additional real-world examples of the tensions between data access, usability, privacy, security, and ethics.
Click on the tab to learn more.
![]()
The same data that can enable responsible, evidence-based decision-making can also raise legitimate privacy concerns. For example, some universities use smartphone apps to monitor student attendance—tracking when students arrive late, leave early, or miss class entirely, especially in large lecture halls with over a hundred students. These apps also record which campus facilities students use, such as libraries or gyms.
Making this data more widely available can help universities better understand student behavior, guide resource investments, or even support emergency alerts (e.g., during an active shooter event).
At the same time, such tracking could inadvertently reveal students’ identities, sensitive FERPA-protected information like grades, or fine-grained real-time student location, all of which raise privacy and safety concerns.
Different subpopulations experience different relationships to data privacy. For example, the right to privacy for disabled individuals is often compromised the moment they seek services or support.
Blind individuals may rely on medical devices with widely varying privacy standards. For example, virtual assistants or devices like Meta AI glasses help individuals navigate the world independently while raising concerns that companies like Meta may share or sell user data.
Disabled individuals may also face structural privacy barriers when accessing medical care. For example, health data for disabled individuals is routinely reported to the Centers for Medicare & Medicaid Services (CMS), often without explicit consent.
Simultaneously, disabled individuals often need their disability status disclosed to properly receive legible, timely, and actionable information. For example, during the Kerr County Flood, emergency evacuation warnings were not effectively issued to allow those with mobility challenges to successfully evacuate.
Those who collect and disseminate data may have different data privacy expectations and obligations than data subjects. For example, during a roundtable discussion hosted by the Council of the Section of Legal Education and Admissions to the American Bar Association (ABA), the ABA focused on reviewing, refining, and expanding demographic data collection practices for students, faculty, and staff.
Some universities may choose to withhold the number of transgender students enrolled in their law schools to protect individual privacy. Since transgender students are frequently a small minority of law student cohorts, choosing not to disclose this information can help protect the identities and “out” statuses of potentially affected transgender students.
While some students preferred this university approach, others preferred accurate representation in the data, believing it helps foster connection among transgender students and signals that their law school was inclusive and welcoming. Different universities reached different outcomes depending on how group representativeness was valued and who was involved in shaping these decisions.
1.2 Defining key stakeholders in the data ecosystem
For these training materials, this is how we define the various stakeholders in the data ecosystem.
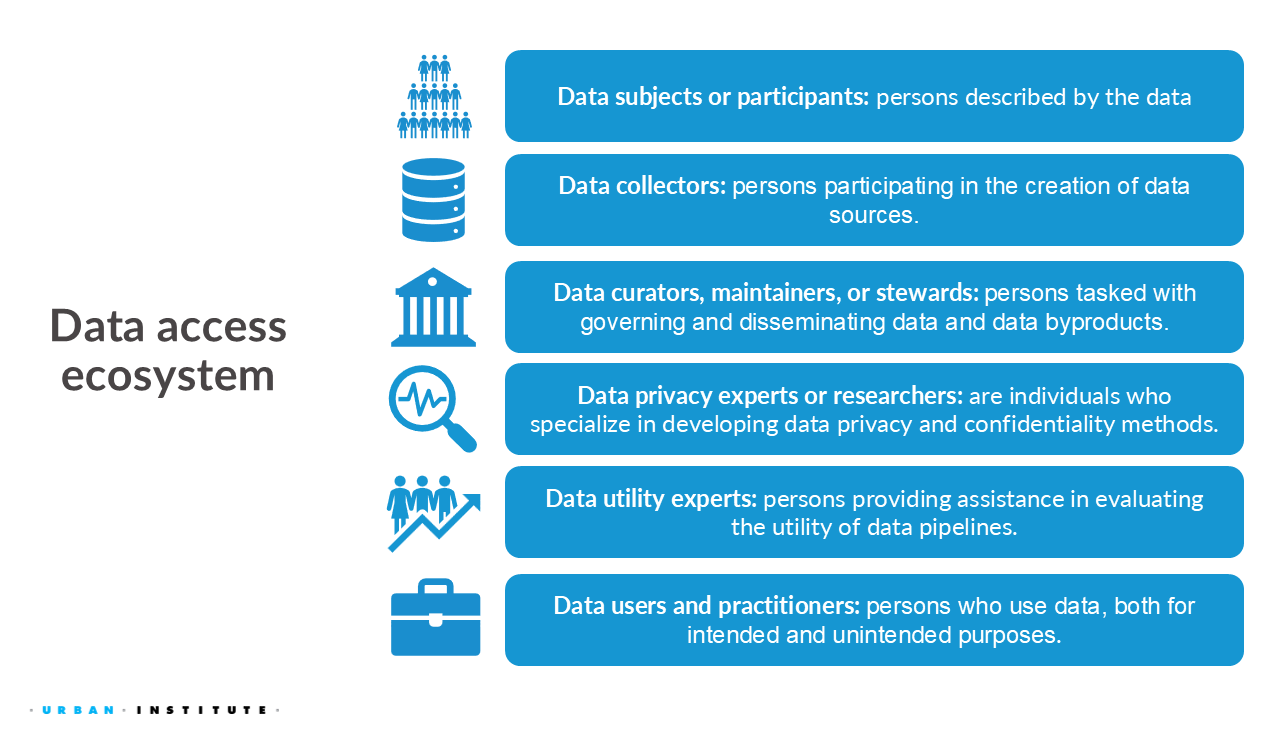
The goal of this training is to equip data curators, practitioners, and other professionals with the technical, legal, and social evidence needed to support their decisions transparently and responsibly to those affected, such as data subjects.
1.3 What are the Dimensions of Data Governance?
Data governance concerns ensuring appropriate flow of information in data processing systems. However, there are countless approaches to both 1) determining what is appropriate flow, and 2) deciding how to ensure appropriate flow. To break it down, we consider…
- Values: how might we want the flow of information to function?
- Perspectives: what disciplinary tools, methods, and frameworks give us guidance on how to govern data?
- Trade-offs: what aspects of data governance are in tension with one another?
1.3.1 Data Governance Values
Accuracy
Accuracy often refers to the quality of available data, ensuring that data meaningfully represents the data subjects.
Why it matters: Inaccurate data can lead to flawed analyses, poor decision-making, and misrepresentation of data subjects.
Key ideas:
- Quantitative and qualitative data quality assessments.
- End-to-end monitoring of data production processes.
Accessibility
Accessibility focuses on what kinds of data are accessible, by whom, and under what conditions.
Why it matters: Data should be available to those who need it for legitimate purposes.
Key ideas:
- Different data access models for different user groups.
- Technologies and policies that enforce different access models.
Usability
Usability ensures that data is understandable, actionable, and fit for purpose.
Why it matters: Highly accurate data is ineffective if users cannot interpret, use it, or otherwise act upon it.
Key ideas:
- Clear and accessible documentation, metadata, and guidance on appropriate or inappropriate use.
- Training and communication strategies for diverse user audiences.
Privacy
Privacy safeguards data subjects’ sensitive information from illegitimate access and use.
Why it matters:
Data curators are ultimately responsible for protecting the privacy rights of data subjects and maintaining their trust.
Key ideas:
- Privacy and security risk assessments.
- Technologies and policies to safely share data products.
1.3.2 Perspectives
Technical perspectives
Technical perspectives on data governance concern technological interventions for controlling data access and use.
Example interventions include, but are not limited to…
- Privacy enhancing technologies (PETS): computational technologies that measure and/or restrict privacy risk in data processing.
- Algorithmic fairness technologies: computational technologies that measure and/or restrict group disparities in data processing.
Legal perspectives
Legal perspectives on data governance concern laws and policies that ensure legally compliant data processing.
Example interventions include, but are not limited to…
- Information privacy laws and their implementation.
- Writing and executing data use agreements and policies.
Ethical perspectives
Ethical perspectives on data governance concern ethical practices for data governance decision-making and justification.
Example interventions include, but are not limited to…
- Data governance codes of conduct.
- Data-subject powered accountability mechanisms.
1.3.3 Trade-offs
Increasing the quantity and quality of available data necessarily increases data subject privacy risks.

Data utility, quality, accuracy, and usefulness is how practically useful and/or accurate the data are for research and analysis purposes.
- Making more higher-quality data easily available necessarily increases the risk of data subject privacy risks.
- Ex1: providing record-level data instead of aggregated data makes it easier to single out individuals in datasets.
- Ex2: providing more detailed demographic data makes it easier to associate records with specific individuals.
- Making data more private necessarily means providing less data or lower-quality data.
- Ex1: Data that has been altered for privacy protection purposes are necessarily harder to analyze than their unprotected counterparts.
- Ex2: Many public datasets have specific data fields entirely removed for privacy purposes, making them unusable.
In other words…
Greater Data Utility
- Data quantity + quality
- Ease of access
- Permitted use and dissemination
Greater Data Privacy
- Technical protections
- Secure architectures
- Rules and regulations
Increasing the ease at which users access data necessarily increases data subject security risks.
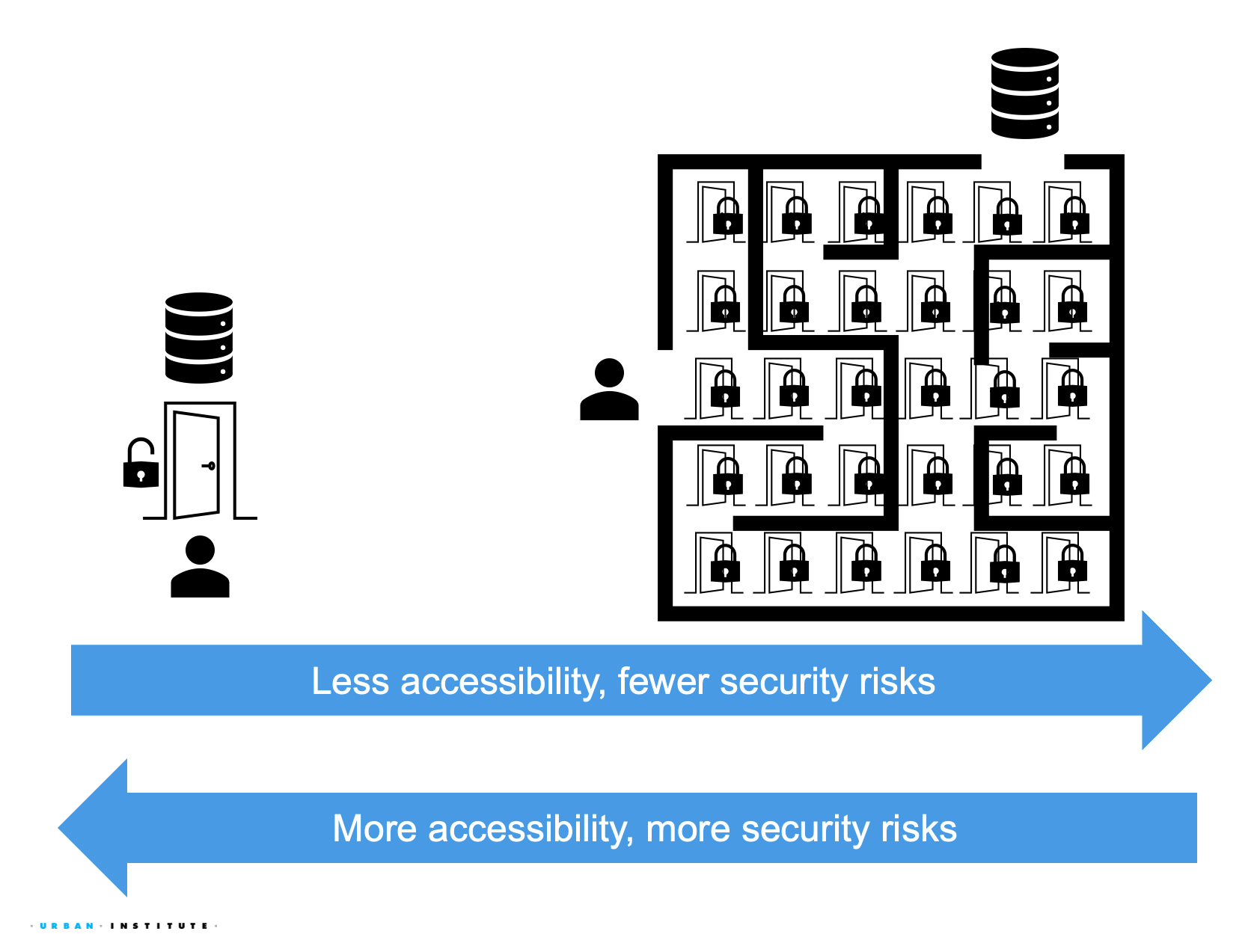
- Making it easier to access data necessarily makes it easier for unintended parties to access data.
- Ex1: hosting data publicly on websites allows automated processes like web crawlers, AI training data processes, etc. to use this data in insecure manners.
- Ex2: insecure file sharing practices (like sharing unencyrpted email attachments with collaborators) increases both convenience and security risks in case of an email breach.
- Making it harder for adversarial actors to access data necessarily increases administrative burdens for intended parties.
- Ex1: multi-factor authentication for data access increases the time needed to gain approval to access a dataset.
- Ex2: analyzing data on secure computing systems can be slower and more burdensome than analyzing data on insecure systems.
Increasing transparency about data processing necessarily reduces the trust in expertise needed to justify data governance decisions, for better and worse.
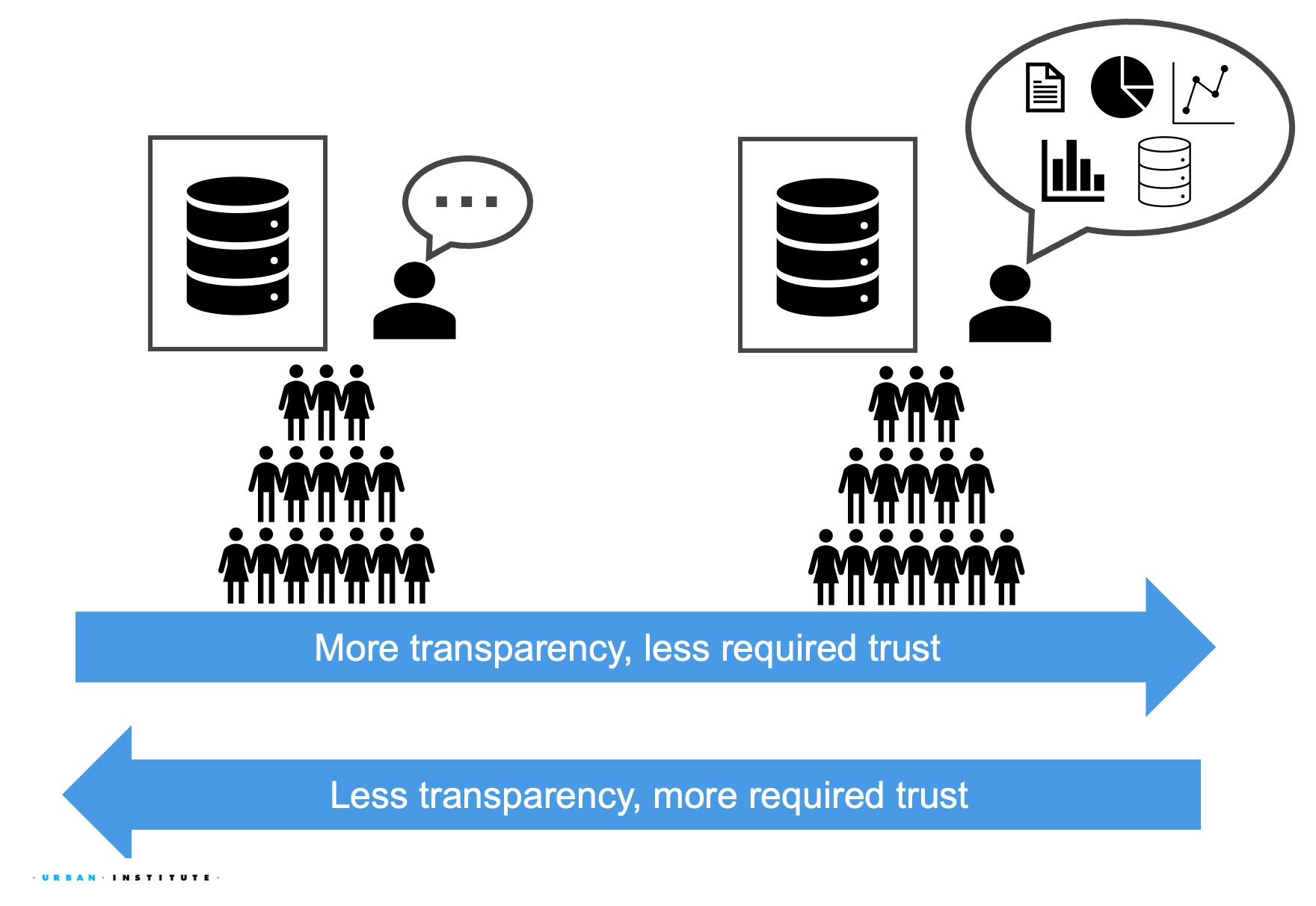
- Failing to share sufficiently transparent information about data processing demands that users put more trust in data curators.
- Ex1: Restricting publicly available information about data collection methods requires users to trust that data was collected in a justifiable manner.
- Ex2: Restricting publicly available information about data processing risks requires users to trust that any risks were properly assessed by the data curators.
- Sharing too much transparent information about data processing can unintentionally undermine trust in expertise needed to make nuanced or ambiguous data governance decisions.
- Ex1: sharing too much transparent information about appropriate or inappropriate use of data may inadvertently discourage otherwise appropriate data use.
- Ex2: sharing too much information about privacy risks associated with a dataset may unintentionally discourage data subjects from participating in data processing.
Data privacy best practices resist simple technical or legal standardization, as effective solutions often depend on nuanced and evolving contexts. All data privacy approaches perform best when evaluated holistically, with attention to the specific social, legal, and technical environments in which they operate. These practices also require navigating disagreements and competing priorities among stakeholders.
1.4 What is Data Governance in the Data Lifecycle?
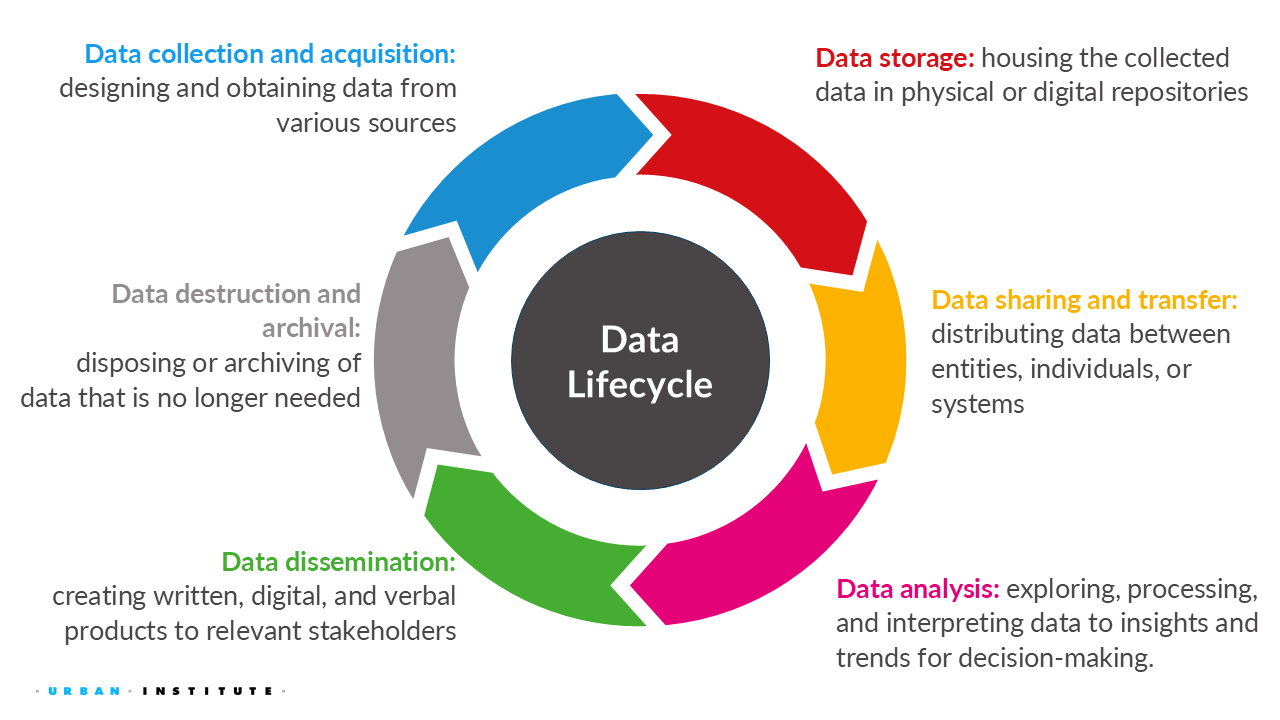
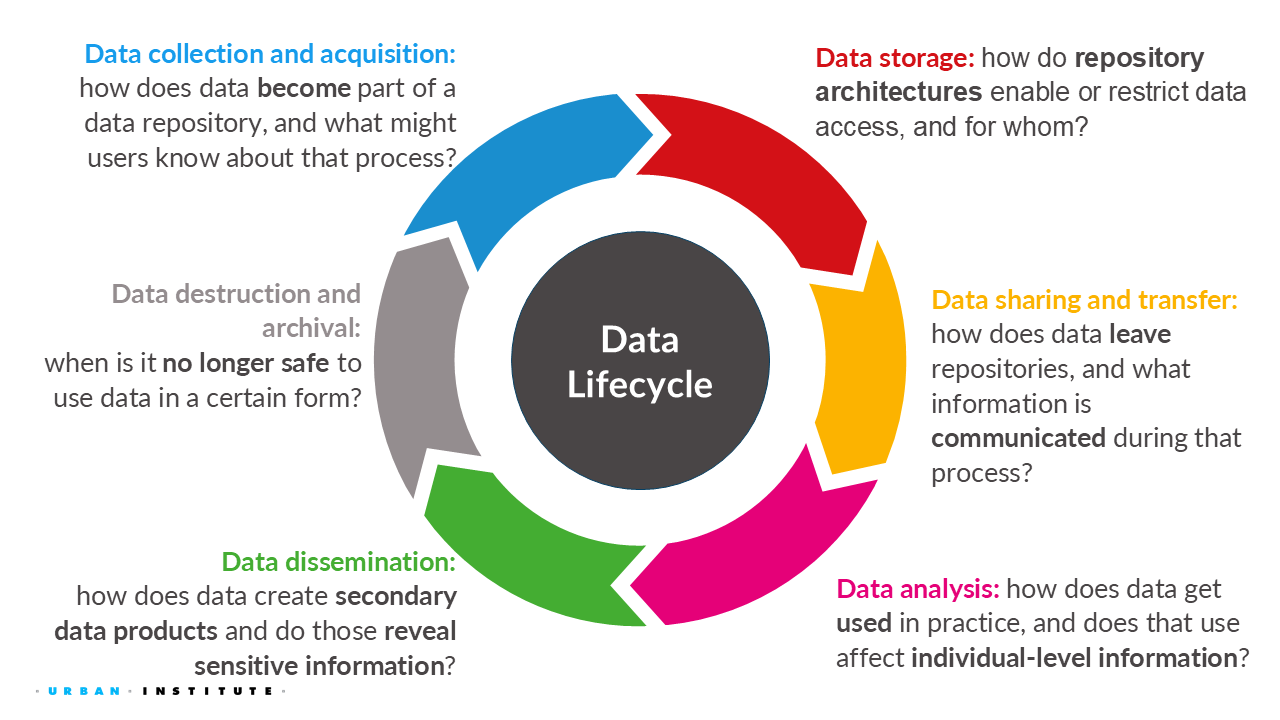
1.4.1 Data governance guiding questions and considerations throughout the data lifecycle
The following are some questions to consider for each stage of the data lifecycle in project planning or proposal development.
- What values form the basis of the data lifecycle associated with this dataset?
- How are these values implemented across each phase of the lifecycle?
- Who or what holds ultimate responsibility for privacy, security, and ethical considerations throughout the data lifecycle, and how is accountability maintained?
1.4.2 Data collection
Why are the data being collected, and who are the intended users?
- What and how data should be collected—or not collected?
- How much do data subjects know about the data are being collected and for their use?
- What kinds of decision-making would only be capable with access to new data, communicating both benefits and risks of data collection to subjects?
- If data are being collected, who designs the data collection process?
- Should demographic information be collected, and if so, how do we minimize risks to different populations when collecting such information?
- How do we balance the need for information with the need to protect communities?
1.4.3 Data storage
What are the privacy and security responsibilities and protections when storing sensitive data?
- Where and how are the data stored?
- What additional information, such as metadata, is stored with the data?
- Are the FAIR principles (Findable, Accessible, Interoperable, Reusable) applied?
- Who has access to the data, how is that access restricted or not, and how do we ensure accessibility in that data access? E.g., secure enclaves, public data files and statistics.
1.4.4 Data sharing
How can data be safely shared and transferred, particularly across levels of government or with external partners?
- What safeguards are needed to ensure responsible sharing?
- How should consent be handled, especially when individuals may agree to share their data with one entity but not another?
- Who decides whether data can be shared or transferred between entities?
1.4.5 Data analysis
How do we ensure proper data analysis?
- How are the data being analyzed?
- Do analysts have the right data and metadata to make informed analytic decisions about whether and how to process data?
- Are there appropriate disclaimers, guidelines, or warnings to ensure outputs are used responsibly after analysis?
1.4.6 Data dissemination
How do the intended data products support their audiences?
- How do we ensure insights are communicated in ways that are accessible, accurate, and useful while minimizing disclosure risks or harm?
- What narratives can emerge from the same dataset, and how might they be framed differently?
- How might audiences react to the insights generated?
1.4.7 Data archive and termination
Are the data subjects being responsibly represented or forgotten?
- How should we inform participants about data destruction policies without hurting the data collection process?
- When is it appropriate to archive data? Are there situations where destroying data could be unethical? e.g., disproportionally impact certain subpopulations?
- How long should data be stored before they are securely destroyed?
- If data are destroyed, what information should be preserved to ensure there is a record of its existence?
1.5 What are the Modes of Accessing Data and Statistics?
There are many versions of the data we should define.
Different levels of security and privacy are needed for different versions of the data. We will mostly focus on the confidential and public versions of the data. However, note that the original or raw data must also be securely stored and properly documented for future reference.
Original dataset is the uncleaned, unprotected version of the data.
For example, raw 2020 Decennial Census microdata, which are never publicly released.
Confidential is a dataset that contains personal or sensitive information that is, in general, not publicly accessible without specific provisions (for example, applying for restricted use permission).
For example, the Census Edited File that is the final confidential data for the 2020 Census. This dataset is never publicly released but may be made available to others who are sworn to protect confidentiality (i.e., Special Sworn Status) and who are provided access in a secure environment, such as a Federal Statistical Research Data Center.
Public dataset is the publicly released version of the confidential data.
For example, the US Census Bureau’s public tables and datasets or the Bureau of Labor Statistics reporting the unemployment rate statistics.
Data users have traditionally gained access to data via:
Direct or secure access to the confidential data if they are trusted users (e.g., obtaining Special Sworn Status to use the Federal Statistical Research Data Centers).
Access to public data or statistics, such as public microdata and summary tables, that the data curators and privacy experts produced with modification to protect confidentiality.
1.5.1 Tiered Access
Tiered access is a data governance model that provides different levels of access to data users based on their needs and disclosure risks of their research projects.
Tiered access can include:
- Public-use data files
- Synthetic public-use data files
- Restricted-use data in online data enclaves
- Restricted-use data in on-premise research centers
- Formally private query systems
The Urban Institute is developing public-use synthetic datasets and formally private validation servers as a model of tiered access in partnership with the Statistics of Income Division at the IRS.
Another example is All of Us Research Hub, one of the largest biomedical data resources of its kind that has data, research tools, and research projects.
1.5.2 Secure data access
Over the years, U.S. government agencies have been moving slowly toward allowing more data users direct access to the underlying cleaned data, under strict controls.
An example of direct data access is through a secure enclave, such as the Federal Statistical Research Data Centers.1 This secure enclave became available in 1982 (then called the Center for Economic Studies), after data users demanded access to better quality data when the US Census Bureau became more aggressive with its applications of statistical data privacy methods on its data products.
Although more secure facilities are becoming available (for example, the National Science Foundation Secure Data Access Facility2), researchers face several challenges to obtaining this direct access. Full access to these data are only available to select U.S. government agencies, a limited number of data users working in collaboration with analysts from those agencies, or through highly selective research programs administered by these agencies. Further, data users are often required to be US citizens, undergo lengthy clearance processes to gain direct access (which can take months or years), and submit extensive research proposals.
As of March 2025, there are 35 Federal Statistical Research Data Centers across the United States. See the U.S. Census Bureau’s webpage on Federal Statistical Research Data Centers for the number and locations.
The 35 Federal Statistical Research Data Centers across the United States (including Puerto Rico!) may seem like enough to be geographically accessible to most data users. But that is not the case. These data centers are primarily located in places with large academic institutions.
Sometimes confidential data will need to be transferred to an external systems for further analysis. The following are two safe options that are standard ensure a secure file transfer:
File transfer using secure electronic connections. Most workplaces have Secure File Transfer Protocol (SFTP) servers to allow external parties to exchange data with them through encrypted connections. This also includes encrypted emails, file transfers to file hosting services (e.g., Dropbox), survey tools (e.g., Qualtrics), and other services using browser-based transfers with Transfer Layer Security (TLS).
File transfers using compressed (e.g., zipped), encrypted, password protected files to emails where the password is shared by another means by phone or text message and the encryption is FIPS 140-2 complaint, usually AES 128 or AES 256.
Do not share data through unencrypted file transfers over the Internet or in the body of, or as an unencrypted attachment to, an unencrypted email. Always consider some form of SFTP!
You can also restrict access by limiting the use of confidential variables. For example, if a file is considered confidential because it contains identifying names and addresses, those variables may be removed from the file and replaced with pseudo identifiers. The sanitized file can then be used and shared without risk of violating confidentiality. You can also regulate access restrictions by limiting people within your workplace from accessing specific computer accounts or files.
1.6 What Even is Data Privacy?
Data privacy is deeply multifaceted!
- Technical controls for controlling data access
- Legal agreements between entities governing data use
- Social norms describing contextual information flows
- Ethical practices for information access decision-making
1.6.1 Privacy and Confidentiality
Data Privacy is determining and enforcing the appropriate flow of personal information through various data processes.
Confidentiality is “the agreement, explicit or implicit, between data subject and data collector regarding the extent to which access by others to personal information is allowed” (Fienberg and Jin 2018).
When reviewing these definitions, it’s important to note that the terms data privacy and confidentiality are often used interchangeably, but they refer to distinct concepts.
Privacy centers on the various flows of personal information in the different processes. In contrast, confidentiality pertains to the responsibility of data curators to protect that information.
Both privacy and confidentiality aim to protect sensitive information and foster trust among the various entities involved in data sharing and access.
Data privacy and confidentiality is a broad topic, which includes data security, encryption, access to data, etc. These materials do not cover privacy breaches from unauthorized access to a database (e.g., hackers).
There are differing notions of what should and shouldn’t be private, which may include being able to opt out of or opt into disclosure protections.
“Federal Statistical Research Data Centers (FSRDCs) are partnerships between federal statistical agencies and leading research institutions. FSRDCs provide secure environments supporting qualified researchers using restricted-access data while protecting respondent confidentiality.” From the U.S. Census Bureau’s webpage on Federal Statistical Research Data Centers.↩︎
The National Science Foundation Secure Access Facility provides authorized researchers secure remote access to National Center for Science and Engineering Statistics data and metadata, such as the Survey of Earned Doctorates and the national Survey of Recent College Graduates.↩︎
Social perspectives
Social perspectives on data governance concern social and normative practices that ensure data governance aligns with data subjects’ social expectations.
Example interventions include, but are not limited to…