2 Introduction to Privacy-Enhancing Technologies

In the previous chapter, you learned about:
- Dimensions of data governance and their privacy implications.
- Kinds of trade-offs associated with disclosure risk.
- Definitions and interpretations of data privacy.
In this chapter, you will learn about:
- Privacy-enhancing technologies (PETs), their components, and uses/misuses.
- Statistical data privacy (SDP) and the tools needed to evaluate output PETs.
2.1 Privacy-Enhancing Technologies (PETs)
Recall the following definitions from the previous lesson:
Data Privacy is determining and enforcing the appropriate flow of personal information through various data processes.
Confidentiality is “the agreement, explicit or implicit, between data subject and data collector regarding the extent to which access by others to personal information is allowed.” (Fienberg and Jin 2018).
In order to understand PETs, we must first understand the kinds of technical privacy harms PETs attempt to mitigate.
Data privacy adversaries (“adversaries” for short) are individuals who try to collect, extract, or otherwise procure data from a computing system in an inappropriate manner.
Data privacy adversaries are known by many names, including intruders, attackers, hackers, snoopers, and others.
- Adversaries aim to receive information that’s typically unintended for them as data users. For example, data privacy adversaries may try to reconstruct personal information from published statistics, even though the published statistics may be intended for a general public audience.
- The inappropriateness of adversaries can stem from many places; adversaries may be acting illegally, unethically, or in violation of organizational policies.
There are two major categories of data privacy threats:
- Input privacy threats occur when adversaries gain unauthorized data access as it is being communicated through data processing to its final audiences. Example threats include:
- An email service provider accessing a file attachment containing raw personal information.
- A large language model reading a file in its context containing sensitive data.
- Output privacy threats occur when adversaries interpret or modify data as it is being published to its final audiences in order to extract sensitive information. Example threats include:
- A table of workplace survey results allows a manager to infer which of their direct reports is the least happy with their manager’s performance.
- A dataset of financial statements allows an auditor to deduce that a business has not paid their taxes properly.
Below you’ll find some input privacy examples:
https://www.bbc.com/news/world-asia-61921222
- Story: an employee lost a physical drive containing sensitive information about a city’s residents while in work transit.
- Lesson: both physical and digital transfers of sensitive data can cause input privacy risks.

- Story: a grocery store’s third-party customer data platform vendor experienced a massive data leak.
- Lesson: input privacy risks depend on everyone who accesses data, including trusted vendors.
https://www.npr.org/2022/09/04/1121061081/irs-data-mistake-public-congress
- Story: confidential tax information was accidentally made available in an IRS search engine.
- Lesson: input privacy issues can arise at any point in the data processing pipeline.
Below you’ll find some output privacy examples:
https://www.census.gov/library/working-papers/2025/adrm/CES-WP-25-57.html
- Story: The U.S. Census Bureau was able to use public historical data to accurately reconstruct millions of 2010 Census responses.
- Lesson: publishing many tabular statistics can be equivalent to publishing the underlying records themselves.

https://news.mit.edu/2015/identify-from-credit-card-metadata-0129
- Story: researchers were able to identify most individuals in a credit card dataset from only 3-4 purchase receipts.
- Lesson: output privacy risks grow rapidly when subjects contribute multiple records or data points to a dataset.
- Story: ChatGPT queries can be used to extract OpenAI’s confidential training data.
- Lesson: modern AI and machine learning models often memorize training data.
2.1.1 What are PETs?
Privacy-Enhancing Technologies (PETs) are critical tools for ensuring responsible data stewardship.
Privacy-enhancing technologies (PETs) are computing technologies that enable safer data sharing while mitigating potential privacy risks.
PETs may refer to algorithmic data processing techniques, hardware configurations, communication protocols, or other computing technologies that address potential privacy risks. In general, PETs can be distinguished into two types:
- Input Privacy PETs aim to protect data communication to prevent unauthorized access during data processing and storage. Examples include:
- Secure multi-party computation (MPC): algorithms that allow multiple parties to compute a function on their joint data without revealing the inputs to one another. For example, the Boston Women’s Workforce Council used MPC to securely aggregate salary data across Boston employers to analyze wage disparities without revealing which employers contributed which pieces of salary data.
- Privacy-preserving record linkage (PPRL): algorithms that allow multiple parties to analyze data on individuals present in multiple datasets without sharing identifying information needed to link records. For example, the National Covid Cohort Collaborative used PPRL to link COVID data across multiple electronic health records systems without directly sharing PHI.
- Federated learning (FL): algorithms that enable iterative training for machine learning, generative AI, or other optimization-based models on local devices to avoid directly transferring sensitive information to a central server. For example, NVIDIA’s Autonomous Vehicles team uses FL to minimize data transfers between autonomous vehicles located in different countries.
- Output Privacy PETs aim to protect data publishing to prevent unauthorized disclosure using published outputs. Examples include:
- Statistical disclosure control (SDC): traditional algorithms that modify statistical data products (usually following deterministic rules) prior to publication to avoid leaking confidential information. For example, the DC Office of the State Superindendent of Education uses different cell suppression policies to determine whether tabular count statistics are safe to publish or require modification or deletion.
- Synthetic data (SD) generation: algorithms that use generative modeling to generate datasets that imitate the statistical properties of confidential datasets while limiting the ability to infer information about individual records within the confidential datasets. For example, the U.S. Census Bureau’s Synthetic Longitudinal Business Database generates synthetic longitudinal data about business establishments and their payrolls and employee counts.
- Differential privacy (DP): algorithms that use randomized noise to estimate statistical outputs while providing a priori or formal disclosure risk limitation properties. For example Apple uses DP to model emoji usage for automatic emoji suggestions within Apple product keyboard interfaces.
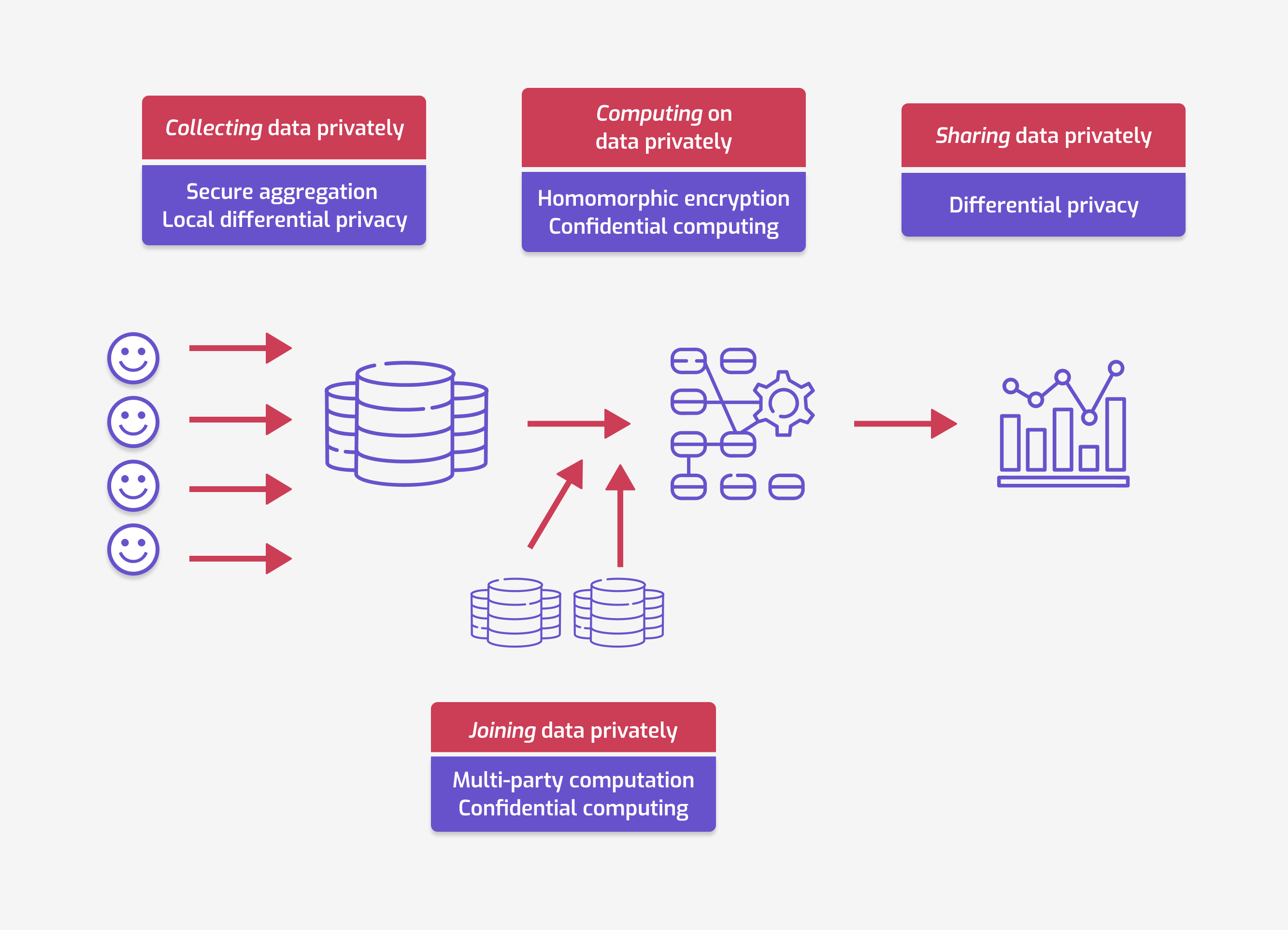
Source: https://www.tmlt.io/resources/mapping-privacy-enhancing-technologies-to-your-use-cases
The majority of future content in this course is focused on output privacy PETs, since the goal is to help organizations more safely disseminate more data.
However, many data governance challenges can and should be addressed by input privacy PETs. Our goal is to help organizations identify and implement the right tools, both technical and non-technical, for their data governance needs.
2.1.2 Why use (or not use) PETs?
As discussed in the previous section, data governance and privacy are highly multifaceted. Because of this multifaceted nature, PETs can only address some, not all, data governance problems. However, there are many common data governance problems where PETs can be helpful:
- Input privacy PETs motivating justification:
- Coordinating data sharing in low trust environments: PETs can help minimize the quantity and quality of information shared between parties that may otherwise adversarially use each other’s information.
- Minimizing data communication between parties: PETs can minimize the amount of data that must be communicated between different parties (often at the expense of greater computational time needed to use the resulting received data).
- Output privacy PETs motivating justifications:
- Expanding access to confidential datasets: PETs are frequently used to release alternative versions of confidential data that can be more widely available.
- Improving disclosure risk assessment and mitigation processes: PETs can help improve existing processes organizations follow for determining when and how to share data products.
There are also many reasons NOT to use PETs!
- “Check-box” legal compliance: the mere presence of any PET does not guarantee compliance with privacy laws or policies. While PETs can make it easier to provide evidence of compliance with privacy laws, it is not a priori necessary or sufficient evidence for compliance.
- Substitute for data subject engagement: using PETs does not obviate the need to engage with data subjects. While PETs can provide evidence of responsible data usage to data subjects, it should not be used to coerce or manipulate data subjects into new data collection or use that would otherwise be inappropriate without engagement.
To safely use PETs for data subject to specific legal protections, ALWAYS consult your organization’s legal resources before pursuing a PET implementation.
- PET implementation affects the entire data collection process, starting with data collection planning, data use agreements, and beyond.
- Many PET vendors, particularly for-profit vendors, may make claims about how using their technologies guarantees certain forms of legal compliance. Always be sure to do your due diligence to verify these claims with your legal resources before pursuing purchasing PET software, hardware, technical assistance, or other support from a vendor.
2.1.3 How do PETs work?
PETs use many different “building blocks” to operate.
- Hardware building blocks:
- Secure computing environments: hardware configurations that physically or computationally isolate data access and use from other input or output processes.
- Trusted third-party computing environments: hardware configurations that use a single trusted endpoint for receiving and aggregating information from multiple parties.
- Query systems: hardware configurations that allow users to ask questions (i.e. queries) about confidential data outputs and receive answers without interacting with the confidential data. Questions may take many forms (SQL-style queries, human-readable text, etc.) and may or may not yield useful answers.
- Software building blocks:
- Data minimization: software techniques for changing the quantity and quality of data shared with other parties or the general public.
- Randomization: software techniques for randomizing outputs to obscure sensitive information.
- Risk measurement: software techniques for measuring privacy risks associated with specific data processing tasks.
Talking about PETs can sometimes be difficult because PETs may or may not encompass many of these building blocks simultaneously!
Differential privacy (DP) is a common output privacy PETs that incorporates many of the building blocks above:
- DP uses mathematical models of query systems to understand how privacy risk accumulates when answering multiple questions about confidential data.
- DP provides formal measurements of privacy risks associated with the properties of specific data sharing algorithms.
- DP uses randomization in query answers to reduce disclosure risks.
Each of these facets includes numerous design choices (which we will discuss in more detail later in the notes).
PETs are not plug-and-play.
Because applying PETs requires engaging with multiple tools, each with many design choices, the effectiveness of PETs is a function of…
- How a particular PET is implemented, and…
- Whether or not the PET is capable of addressing substantive privacy concerns.
Weaknesses with either problem 1) or 2) can cause real-world harm!
- Example for 1), consider Apple’s DP implementation. Apple uses differential privacy for many different models based on sensitive user data. However, the way in which Apple implemented DP has raised many concerns from privacy advocates, particularly around insufficient randomization and the temporal nature of Apple’s data.
- Example for 2), consider Google’s “federated learning of cohorts” (FLoC). Google proposed FLoC as a federated-learning replacement for cookies used by internet browsers (typically for advertising purposes). However, the project was discontinued when users and privacy advocates raised concerns that FL was addressing input privacy problems, not output privacy problems associated with web browsing data.
2.2 Statistical Data Privacy (SDP) and PETs
2.2.1 What is SDP and how does it relate to PETS?
Statistical data privacy (SDP) is a broad term used to describe the study of data publishing techniques that enable population-level inferences from confidential data while limiting individual-level inferences from confidential data.
SDP is most closely associated with output privacy PETs, as most of these technologies are ultimately designed to measure and mitigate disclosure risk associated with public data products.
2.2.2 Privacy Risks with SDP and Output PETs
Traditional privacy approaches often classify data into categories such as:
- Personally Identifiable Information (PII): Data that can be conceptually linked to an individual for identification purposes (e.g., names, addresses, Social Security numbers).
- Sensitive Information: Data protected by legal frameworks or shaped by social norms that restrict access (e.g., tax records, student transcripts).
However, context matters! Under the right conditions, any type of data can become identifying or sensitive. This underscores the need for flexible, context-aware privacy strategies that go beyond rigid classifications of confidential data properties.
Instead of framing disclosure risk around the properties of confidential data (i.e., is a particular field sensitive or not?), SDP frames disclosure risk around the degree to which one could infer confidential data (i.e., can I infer the value of a specific field, and when might that be problematic?).
Direct identifiers are data elements that a priori correspond to a natural person, like names, addresses, unique government identifiers, etc.
Indirect identifiers are any other data elements that, in combination, could be used to isolate or single out an individual. Sometimes, sets of indirect identifiers are referred to as quasi-identifiers.

There are three main kinds of disclosure risk inferences associated with output privacy:
Identity Inference: Can I determine whether a specific record in a dataset belongs to a particular individual?
In other words: can I associate records with a direct identifier?
Example: “Is this record about a California government employee actually about me?”
Membership Inference: Can I determine whether an individual is included in a dataset?
In other words, can I use direct or indirect identifiers to infer the presence or absence of an individual in a dataset?
Example: “Does this data reveal whether I was ever a student in the UC school system?”
Attribute Inference: Can I infer the value of a specific attribute about an individual?
In other words, can I use indirect identifiers to infer an attribute value?
Example: “Does the data reveal when I graduated from UC Berkeley?”
Different PETs focus on different forms of risk:
- Non-randomized PETs (like SDC) typically aim to limit identity inference, but may enable membership inference.
- Randomized PETs (like DP or synthetic data) typically aim to limit membership inferences, but may enable attribute inference.
Attribute inference is frequently misinterpreted because it can simultaneously indicate both a privacy risk and useful data outputs.
For example, suppose a confidential dataset reveals a relationship between a student’s GPA and their score on a standardized exam. Theoretically, if one knew a student’s GPA, they could infer (with some uncertainty) that same student’s score on a standardized exam. To assess whether this inference is privacy-concerning, one might ask questions such as…
- Does this relationship reflect the broader population of students or is the relationship specific to the students in the confidential data?
- How does the quality of the attribute inference differ across individuals in the confidential data, in particular for individuals with higher membership inference risks?
Deciding which output privacy PET to use can be a difficult task, since each tool frames technical and policy decisions about the privacy-utility trade-off diffferently. The following self-evaluation questions can help you decide which approach or approaches to consider when implementing output privacy PETs (we will discuss each in greater detail in later sections):
- Ask yourself which data formats are most important to users:
- Synthetic data approaches maximize interoperability with existing data processing systems.
- Query-based approaches maximize efficient privacy-utility trade-offs.
- Ask yourself what kinds of disclosure risk measurements address your organization’s needs:
- Empirical disclosure risk metrics, associated with traditional synthetic data, use realized disclosure risks to provide lower bounds on the feasibility of specific privacy-concerning inferences.
- Formal disclosure risk metrics, associated with differential privacy, use formal analysis of randomization to provide upper bounds on generic privacy-concerning inferences.
- Ask yourself what kinds of output modifications are acceptable to users:
- Non-randomized methods are easier to interpret for administrative (or data-specific) purposes but generally have much weaker disclosure risk protections.
- Randomized methods are easier to interpret for statistical (or model-parameter-specific) purposes and generally have stronger disclosure risk protections.
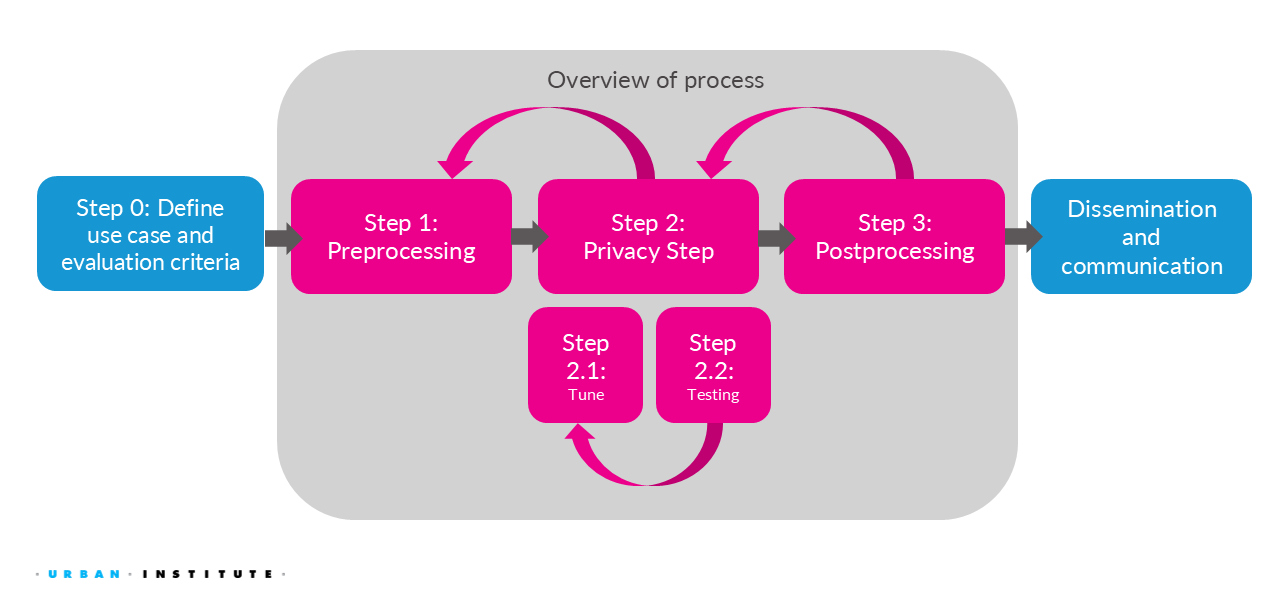
2.3 Output Privacy PET Workflow